What Should NDS Provide?
Simply put, the National Data Service should make it easy to find, use, and publish data. It should provide a common set of services that can work across communities and disciplines, but it should also build on top of existing infrastructure already put into place by those communities. NDS services should have a strong connection to publications and publishing process to ensure that robust links between published literature and the data they discuss. Through these links, it should be possible to make data as citable as literature.
Core Capabilities
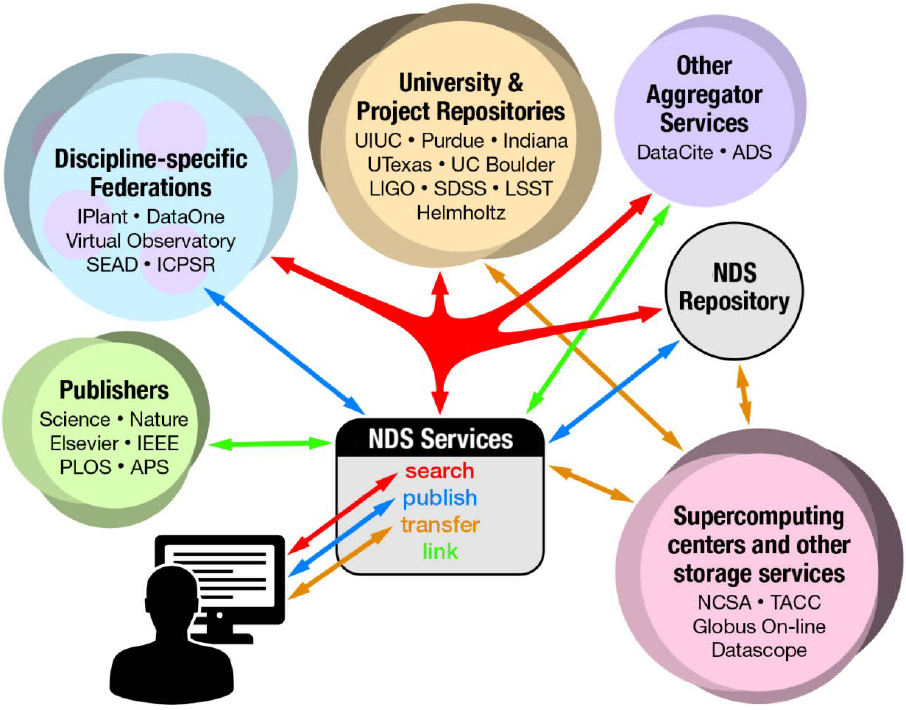
We envision a core set of NDS end-user tools and services that connect researchers to the rich array of data resources available over the network. These tools and services would cover four basic capabilities:
- searching for data
- moving data, both between different repositories and between repositories and computing platforms
- sharing and publishing data
- creating, maintaining, and tracking links between data and literature
Helping researchers find data
The NDS should allow users easily search for data across disciplinary boundaries related to particular scientific topics. They should be able to browse data collection metadata, locate the repositories containing relevant data, and to download the data for re-use. Since cross-disciplinary search constraints will likely be crude, it is critical that users be able to drill down to leverage community-specific discovery tools provided by specific federations or individual repositories.
Often, researchers will need to find the data related a particular published article. They may need access to the primary collection that the article's analysis is based on, or it could be data cited by article but described in other publications. Tools for managing data citations and tracking data provenance will become as necessary as the need to manage citations to the articles.
NDS tools for high-level searching needs to deal with two key challenges common in digital-data research. First is the problem of large search results: researchers need ways of quickly isolating collections that are most relevant to their research. This might include categorizing or faceting results, as well as drilling down to community-specific discovery tools that can leverage discipline specific metadata. Researchers should be able to readily see within which communities certain topics are "hot"—i.e. where most of the related data are being produced, but they should also be able to find the unexpected datasets from related communities. The second challenge is in managing large data collections once it becomes time to use the data.
Helping researchers use data
Helping researchers use the data they've discovered goes beyond simply downloading the data. They need access to the good quality metadata and be able to track data provenance. They also need access to the models that came out of the original research, as well as the software used to process and analyze the data. A wide variety of formats—some standard and some not—are used for science datasets; tools that can help researchers extract metadata, understand their contents, and covert them to other formats will be needed.
As our data collections grow ever larger, so will our scientific questions. In many cases, downloading data to one's local laptop or workstation is not practical. In these cases, the researcher will need to turn to remote platforms, such as supercomputing facilities, science gateways, archive-local services, or campus computing facilities to process and analyze the data. Being able easily copy data from its long-term archive to other repositories or computing platforms is critical for enabling data re-use. This requires not only robust data transfer tools but also high-performance networks between the various universities and institutions that provide data and services.
Helping researchers share and publish data
A key to enabling the re-use of data will be encouraging researchers to publish their data; the NDS needs to provide a framework that does just that. The best way to do that is to engage the scientist early in the publishing process.
The NDS should provide repositories that allow researchers to organize their data and prepare it for publication. This might include not only original data but also data from other repositories, perhaps discovered through the NDS or one of its member resources. Prior to publication, researchers need to be able to share the data privately with their collaborators. They will need tools for organizing data into collections and enriching them with important metadata. Digital Object Identifiers (DOIs) should be assigned automatically so that they can be made available to publishers for linking to articles. The "publishing" of the data—i.e. the step of making the data more broadly available—should be synchronized with the publishing of the related article.
The publishing step can involve migrating the data collection to an appropriate discipline, community, or campus archive for long term preservation. To aid with this, the NDS can provide a "repository recommender service" that can suggest possibly appropriate repositories
Linking Data and Literature
Robust connections between published articles and data are key to each of the core capabilites of searching, using, and sharing data:
- researchers need to be able to find the data described in an article
- to re-use date or verify analysis results, researchers need to find the articles that describe not only the data and models, but also those that describe the software and the precursor data.
- to ensure that new data can be discovered and re-used, data preparation must be built in naturally to the publishing process.
Persistent identifiers are key to establishing the links. This includes not only DOIs for the data products but also ORCIDs for tracking authors.
Using the NDS: a scenario
To illustrate how a scientist might use the NDS, consider this scenario for astronomy research which we think can be realized:
In 2021 the LIGO gravitational wave observatory detects a strong “transient” burst event with an unknown source; an alert is issued. Across the US, physicists and astronomers (who have never worked directly together) engage NDS discovery services to find relevant data from other instruments, leading them to detections from the IceCube neutrino observatory, further isolating the originating portion of the sky. NDS discovery services connect the researchers to the federated discovery tools of the Virtual Observatory to collect data by sky position from large surveys like DES and LSST to look for electromagnetic precursors. Through literature searches, they find publications describing characteristics of similar detections; recent publications and an arXiv preprint supporting NDS data linking lead them to the data underlying the analyses.
They use NDS data transfer services to migrate previous detection data as well as simulation data held at the Blue Waters supercomputing system, containing previously unpublished neutrino emission predictions, to DataScope, a specialized computing platform to compare observations with theoretical models. From this analysis, a crucial insight suggests a new class of stellar object. Using NDS transfer tools, they pull together the LIGO data, corresponding IceCube detections, image cutouts from LSST, and analyses of simulation data into their private space in an NDS repository. NDS metadata generation tools help them organize a new collection.
Soon, a paper is submitted to a journal, including identifiers for the new data collection. Once the paper is accepted, the NDS data collection is sent to a campus archive for longer-term curated management. With the new publication, readers have direct access to the underlying data, enabling them to verify and extend the results. Results and data are further available to educators, who bring the discovery to a broad audience by updating astronomy e-textbooks.